There is a conversation happening in the most capable AI teams right now that is almost entirely absent from the boardroom. It is not about which cloud subscription to buy, which enterprise licence to renew, or which new model has topped a benchmark. It is about what you can run privately, cheaply, and completely under your own control, on hardware you already own.
Local AI. And for most businesses, it remains an almost entirely unexplored advantage.
The Subscription Assumption
The default assumption when most businesses think about AI is cloud. You access a model through an API or an interface, data travels to a server somewhere, a response comes back, and you pay per use or per seat. For many tasks, this is entirely appropriate. The frontier models, the most capable systems for complex reasoning and generation, live in the cloud for good reason.
But here is what the subscription-first mindset misses entirely: not every task you do with AI needs a sledgehammer. Not every conversation you want to have with a model needs to leave your building. And not every process you want to automate needs to generate a monthly invoice from a provider who can change their pricing, their terms, or their model behaviour overnight.
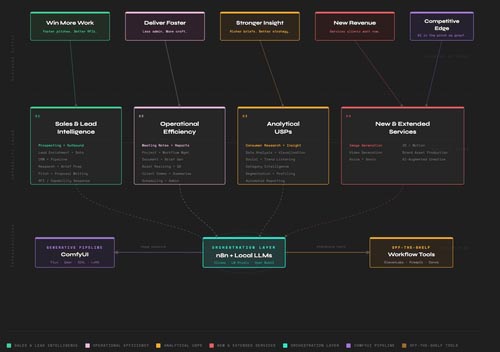
The professionals who are genuinely ahead in this space are running a hybrid operation. Cloud where it earns its cost. Local where it is smarter to do so. And they know the difference.
Four Reasons Local AI Changes the Calculation
Cost at scale. Cloud models charge per token, per query, per seat. For light, occasional use that arithmetic is fine. For high-volume workflows, the kind of automated, repetitive processing that delivers real operational leverage, the numbers compound quickly. One fintech firm reported spending $47,000 a month running GPT-4o Mini through an API before migrating to a hybrid model. Local deployment requires an upfront hardware investment, but the running cost is essentially zero. For consistent, high-volume use, local typically pays for itself within a year.
Privacy that is structural, not contractual. When you send data to a cloud model, you are trusting a contractual promise. Your client briefs, your strategic documents, your commercially sensitive creative, your internal communications, they travel to an external server. The privacy protections around that are real, but they are promises, not physics. Local AI changes the nature of the guarantee entirely. The data never leaves your machine. Not claimed, not promised. Simply impossible, by architecture. For any business handling client confidences, that distinction matters more than most have considered.
Creative and brand control. Cloud models are general purpose by design. They are tuned to serve millions of users across millions of use cases. Local models can be fine-tuned, specialised, and shaped to your brand's specific voice, values, and creative constraints in a way that a shared cloud service cannot easily be. The businesses building genuine brand intelligence into their AI infrastructure are doing it locally, with models trained or adjusted on their own data, their own tone, their own creative standards. That is not possible at cloud scale.
Independence from the platform cycle. Cloud providers change. Models are deprecated. Pricing shifts. Access is throttled. APIs evolve. Every business built entirely on external AI infrastructure is one pricing decision or terms-of-service update away from a workflow disruption. Local infrastructure is yours. It does not change unless you change it. In an environment where the technology moves at the pace it currently does, that stability is genuinely valuable.
What Is Actually Possible on Hardware You Already Own
This is where many people are genuinely surprised, and where the gap between what the informed few know and what most businesses assume is widest.
A current MacBook Pro with Apple Silicon, the M3 or M4 series, the machine sitting on your creative director's desk right now, is capable of running genuinely useful language models locally with no internet connection, no API key, and no monthly fee. Tools like Ollama and LM Studio have made this straightforward enough that setup takes minutes. Models like Mistral, Llama 3, and Phi-4 run on consumer hardware and deliver results that, for a wide range of business tasks, are competitive with paid cloud services.
Apple's unified memory architecture, the way Apple Silicon chips share RAM between CPU and GPU, turns out to be particularly well suited to local AI inference. A MacBook Pro with 32GB of unified memory can run quantised models at 30 to 60 tokens per second, fast enough for real work, private enough for client work, and free enough for workflow work.
This is not theoretical. It is running right now, today, on machines like the ones in your office, being used by the teams that understand what they are looking at.
Think Small. The SLM Advantage.
Not every task needs the most powerful model available. This is a fundamental misalignment between how most businesses think about AI and how the most effective operators actually use it.
Large language models are extraordinary. They are also expensive to query, slow to run locally, and in many cases comically over-specified for the task at hand. Asking a frontier model to do a brand compliance check, classify incoming feedback, reformat structured data, or run a first-pass filter on creative output is the equivalent of hiring a world-class surgeon to put on a plaster.
Small Language Models, SLMs, the lighter, faster, more focused models in the 3 to 13 billion parameter range, are the overlooked workhorse of a properly designed AI operation. They run locally with ease. They are fast. They are cheap to zero cost in operation. And for well-defined, specific tasks they are not meaningfully worse than their much larger counterparts. Often they are better, because their smaller scope makes them more precise.
The ability to identify which tasks need a large model and which tasks are served just as well by a small one is a real skill. It is also a significant cost and speed advantage for the businesses that develop it.
The Deeper Point: Understanding the Fabric
The notes for this chapter include a phrase worth sitting with: start understanding the fabric of AI.
Most businesses are sitting on the surface of this technology. They are interacting with interfaces, not infrastructure. They know what the output looks like but not what is producing it, how it works, what it costs at a deeper level, or what becomes possible when you move below the chat window and engage with the underlying architecture.
Understanding local AI is one of the most direct routes into that deeper layer. Because the moment you are running a model on your own machine, you are no longer a consumer of a service. You are an operator of infrastructure. You start to understand model sizes, quantisation, context windows, memory requirements. You start to see that the choice between models is not just "which is best" but "which is right for this task, this context, this constraint." You start to build genuine technical literacy rather than feature familiarity.
That literacy is the foundation on which the real competitive advantages in this space are being built.
What This Is Not
Local AI is not a replacement for cloud AI. The frontier models, the most capable systems for complex, nuanced, high-stakes tasks, remain in the cloud, and rightly so. The argument here is not either/or. It is that most businesses have not even considered the local option, and in not considering it, they are paying for more than they need, protecting their data less than they should, and leaving a genuine capability lever unpulled.
The businesses that are winning in this space are not the ones running everything locally. They are the ones running the right things locally, and knowing exactly which those are.
The Challenge
Look at the AI tasks your business or team runs most regularly. Pick three that are repetitive, well-defined, and do not require the most complex reasoning available. Then ask: does this actually need to go to an external server? Does this need to be billed per query? Could this run locally, privately, and at zero marginal cost?
If you have an Apple Silicon Mac and have never opened Ollama or LM Studio, the barrier to finding out is genuinely lower than you think. The machine on your desk may already be a capable, private, cost-free AI operator. You just have not introduced yourself yet.
NAITIV exists to demystify the AI advantage and make it real for businesses ready to lead rather than follow. If this opened a door you did not know existed, share it with the person in your team managing your AI spend.